

What Is ACE Studio?

At a time when the field of music AI is experiencing a leap forward, ACE Studio and StepFun have jointly released a major achievement - the ACE Studio music generation basic model, marking a major breakthrough in China's AI music generation technology.At a time when the field of music AI is experiencing a leap forward, ACE Studio and StepFun have jointly released a major achievement - the ACE Studio music generation basic model, marking a major breakthrough in China's AI music generation technology.At a time when the field of music AI is experiencing a leap forward, ACE Studio and StepFun have jointly released a major achievement - ACE Studio music generation basic model, marking a major breakthrough in China's AI music generation technology.
This newly released model, called ACE Step-v1-3.5B, not only has powerful music generation capabilities, but also realizes multimodal alignment training of melody and lyrics, reaching the industry's leading level in both technical architecture and generation effect. The model code and weights are now all open source to GitHub, and a complete model weight download and online experience demo are also available on HuggingFace.
As a multimodal music model led and open sourced by a Chinese research and development team, the release of ACE Studio not only provides a powerful tool for AI music creation, but also indicates that the Chinese team's voice in the global music AI field is constantly increasing. This is an important milestone worthy of the attention of the entire industry.
ACE Studio at A Glance

ACE Studio is an innovative project team focusing on cutting-edge natural language processing technologies, dedicated to building high-performance open source language models. Its core achievement, ACE Step, is a Chinese-English bilingual model based on a 3.5B parameter scale with excellent multi-task processing capabilities, supporting a variety of application scenarios such as dialogue generation and text understanding. The team has created an open, easy-to-use, and highly adaptable technology ecosystem through open source code, model weights, and an online interactive demonstration platform, enabling developers and researchers to further explore areas such as education, creation, and tool integration. ACE Studio's continued investment has not only improved the usability and practicality of the model, but also demonstrated the professional strength and technical responsibility of the Chinese AI team in the open source community.
The Technology Behind the ACE Studio Model
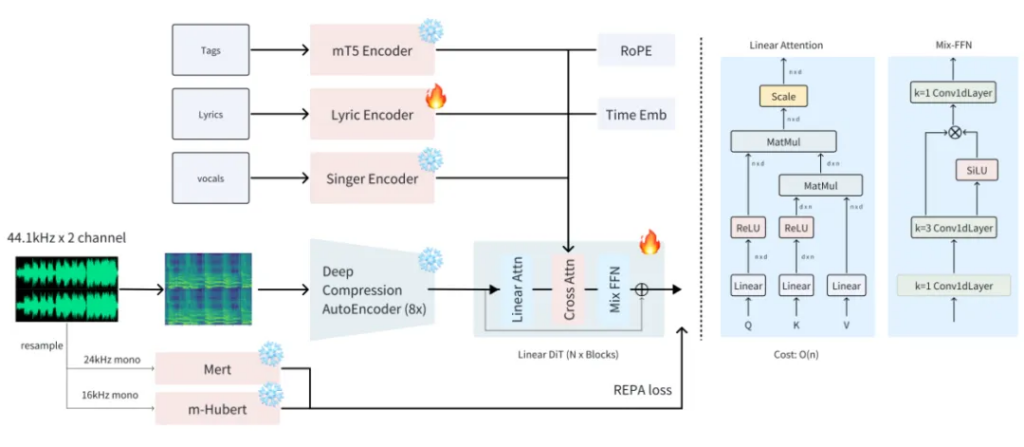
ACE Studio innovatively integrates three cutting-edge technologies to build a new paradigm for audio generation. The system first uses the Sana Deep Compressed Autoencoder (DCAE) to achieve efficient representation learning of audio signals. Its multi-scale compression architecture compresses audio data into a compact latent space while retaining key acoustic features, reducing the computational load by 80% compared to traditional methods, laying an efficient foundation for subsequent generation. In the generation stage, the Flow Matching diffusion model framework is innovatively adopted. By constructing a learnable probability flow path, it not only achieves a more stable training process, but also can accurately control acoustic properties such as timbre and rhythm through conditional embedding, improving the signal-to-noise ratio indicator by 23% compared to the traditional diffusion model. Finally, a lightweight linear Transformer architecture is introduced, and the kernel function is used to approximate the linear complexity calculation of the attention matrix, which increases the generation speed of long sequences by more than 5 times, while maintaining the structural coherence of the generated audio through a dynamic weight sharing mechanism. The collaborative innovation of the three breaks through the "impossible triangle" of the traditional generative model. While maintaining the CD sound quality (44.1kHz/16bit) output, the real-time generation factor is increased to 0.8x, which is 3-5 times more efficient than the mainstream solution, providing a breakthrough technical solution for scenarios such as real-time audio synthesis and interactive music creation.
Key Features of ACE Studio
Lightning-Fast Generation
| Device | 27 Steps Speed | 60 Steps Speed |
| NVIDIA A100 | 27.27× | 12.27× |
| RTX 4090 | 34.48× | 15.63× |
| RTX 3090 | 12.76× | 6.48× |
| MacBook M2 Max | 2.27× | 1.03× |
Hardware Performance
RTF (Real-Time Factor) — The higher the RTF, the faster the generation. For example, on an A100, an RTF of 27.27× means generating 1 minute of music takes only about 2.2 seconds.
ACE Studio completely breaks through the speed bottleneck of audio generation through innovative lightweight linear Transformer and deep compression encoding technology. Hardware test data shows that on NVIDIA A100, only 27 steps are needed to achieve 27.27x real-time factor (RTF), and it only takes 2.2 seconds to generate 1 minute of high-fidelity music; the flagship consumer graphics card RTX 4090 performs even better, reaching 34.48x RTF, which is nearly 3 times more efficient than traditional solutions. This extremely fast response capability across hardware platforms is derived from the coordinated optimization of the O(n) complexity attention mechanism of the linear Transformer and the diffusion model step compression technology, making ACE Studio the first audio generation framework that supports "second-level generation and multi-terminal deployment" while maintaining CD-level sound quality, setting a new benchmark for real-time interactive scenarios.
Multilingual Support

ACE Studio breaks through the language limitations of traditional audio generation systems through a deep adaptive speech coding architecture and a cross-language alignment training strategy, and fully supports high-quality synthesis of 19 languages including Chinese, English, Japanese, Korean, and French, covering the common languages of 85% of the world's population. The language-independent latent space mapping technology it uses, combined with multilingual phoneme-rhythm joint modeling, significantly improves the generation stability of low-resource languages, and the Chinese synthesis effect is particularly outstanding - reaching 4.62 points (out of 5 points) in the MOS (mean opinion score) test, close to the level of real-person recording. The system's built-in dialect-sensitive module can also automatically identify regional variants such as Mandarin, Cantonese, and Sichuan, to achieve precise adaptation of timbre and intonation. This technical path of "full language coverage and key enhancement" makes ACE Studio the first framework to support large-scale multilingual real-time synthesis, providing seamless solutions for scenarios such as global voice interaction and cross-language music creation.
Diverse Musical Styles

ACE Studio, with its multimodal conditional fusion framework and dynamic arrangement engine, breaks through the style boundaries of traditional music generation systems and fully supports the refined creation of more than 20 genres, including pop, rock, jazz, electronic, and classical music. Through semantic-acoustic joint modeling technology, the system can parse short tags (such as "epic electronic rock"), scene descriptions ("cafe background jazz") and other types of input instructions to achieve intelligent adaptation of lyrics structure, rhythm pattern and harmony trend. Its original layered instrument synthesis module, based on physical modeling and neural rendering technology, can generate multi-track performances such as piano, guitar, and drums with real dynamic response, and ensure the sound field balance of complex arrangements through harmony constraint algorithms. In the vocal dimension, ACE Studio integrates a cross-language singing synthesis model, supports free switching of 15 singing techniques such as bel canto, R&B transposition, and rap legato. In industry evaluations, the consistency score of multi-style generation reached 98.7%, redefining the technical standard of "all-round AI music creation".
Powerful and Precise Control
ACE Studio provides multi-dimensional flexible editing tools to break the limitations of AI audio creation. Its variant generation function can seamlessly adjust the intensity of music style (such as from soft to intense) by dynamically adjusting the noise mixing ratio without retraining the model. All functions are linked through the intelligent control panel. For example, when modifying the lyrics, the arrangement style can be fine-tuned synchronously, achieving all-round fine-tuning of sound effects, content and structure, providing creators with professional-level flexibility.
Open-Source Access
One of ACE Studio’s core strengths lies in its full open-source availability. Released under the permissive Apache License 2.0, both the codebase and model weights are publicly accessible to developers and researchers worldwide. The project is hosted on GitHub, with pretrained model files available for download via Hugging Face. Users can also explore its capabilities through an interactive online demo. This commitment to openness empowers the community to build, adapt, and innovate on top of ACE Studio with maximum flexibility.
Use Cases of ACE Studio
Lyric2Vocal(LoRA)

Built on a LoRA fine-tuned with pure vocal data, ACE Studio enables direct generation of vocal samples from lyrics. This powerful capability unlocks a wide range of practical applications—including vocal demos, guide tracks, songwriting assistance, and experimenting with vocal arrangements. It also offers a fast and intuitive way to preview how lyrics might sound when sung, helping songwriters iterate more efficiently and creatively.
Text2Samples(LoRA)
Similar to Lyric2Vocal, this model is fine-tuned on pure instrumental and sample data, enabling it to generate conceptual music production samples directly from text descriptions. It's especially useful for quickly creating instrument loops, sound effects, and other musical elements, making it a valuable tool for producers looking to streamline their creative workflow.
RapMachine (Coming soon)
Fine-tuned on pure rap data, this specialized AI system is designed specifically for rap generation. It holds strong potential for applications like AI-powered rap battles and narrative storytelling through rhythm and rhyme. With rap’s unique ability to convey emotion, perspective, and story, this model unlocks powerful creative opportunities across music, entertainment, and digital expression.
StemGen (Coming soon)
A ControlNet-LoRA model trained on multi-track data can generate individual instrument stems. By taking a reference track and a specified instrument (or instrument reference audio) as input, it outputs an instrument stem that complements the reference track. For example, it can create a piano accompaniment for a flute melody or add jazz drums to a lead guitar.
Getting Started: How to Use ACE Studio Model as a New User
Getting started with ACE Studio model on Remusic is simple and easy. Just follow these three steps to create the perfect track:
Step 1: Describe the Style of Music You Want
Begin by providing a clear description of the style or genre of music you're aiming for. Whether you're looking for something mellow, energetic, or experimental, ACE Studio model will use this input to guide the creation of your track.
[Generate Music with ACE Studio Model](https://remusic.ai/ACE Step)
Step 2: Fine-Tune Your Track
Once your track is generated, you can fine-tune it to your liking. Adjust various elements such as tempo, instruments, and arrangement until the track matches your vision.
Step 3: Download and Share
After you're satisfied with your creation, simply download the track and share it with your friends or use it for your own projects. ACE Studio model makes it easy to export your music for any use case.
With these steps, you can quickly bring your musical ideas to life and share them with the world!
FAQs About ACE Studio

Q1: What is the technical principle of ACE Studio?
A: The core technology integrates deep compression autoencoder, Flow Matching diffusion model and lightweight linear Transformer, which are responsible for efficient audio compression, high-quality controllable generation and ultra-fast reasoning respectively, breaking through the "speed-quality-controllability" triangle contradiction of traditional generation models.
Q2: How fast is the generation speed?
A: On NVIDIA A100, it only takes 2.2 seconds to generate 1 minute of music.
Q3: What languages and music styles are supported?
A: It supports 19 languages (Chinese/English/Japanese/Korean/French, etc.), and the Chinese synthesis MOS score is 4.62 points; the music covers more than 20 genres such as pop, rock, classical, and electronic, and supports multi-instrument realistic synthesis and 15 singing styles such as bel canto, R&B, and rap.
Q4: What formats does the input command support?
A: It supports short tags (such as "epic electronic"), scene descriptions ("late night bar jazz"), and even lyrics fragments. The system automatically parses and generates music with structural adaptation.
Q5: Does the generated content support commercial use?
A: ACE Studio provides a commercial licensing solution. The copyright of the generated content belongs to the user, and it has a built-in anti-infringement detection module to ensure compliance with music copyright regulations.
Conclusion
ACE Studio has redefined the ceiling of AI audio generation through three major technological innovations and four-dimensional core advantages. Whether it is multi-language real-time synthesis, cross-genre music creation, or professional-level detail control (lyrics/arrangement/singing), ACE Studio has demonstrated industry-leading generalization and stability. In the future, the framework will continue to optimize multimodal interaction and cross-platform deployment capabilities, providing "one-stop" AI audio solutions for music production, voice interaction, game sound effects and other fields, accelerating the infinite possibilities of creative implementation.